 Pierwsze udane próby wykorzystania kart graficznych do zaawansowanych wysokowydajnych obliczeń miały miejsce w listopadzie 2004 roku. Wtedy zespół naukowców z laboratorium w Los Alamos wspólnie z inżynierami z Nvidii opracował program wykonujący na karcie Nvidia Quadro FX 3400 obliczenia związane z symulacją zapadającej się gwiazdy. Karta graficzna wykonała te obliczenia czterokrotnie szybciej niż procesor Intel Pentium 4 Xeon 3.0 GHz.
Pierwsze udane próby wykorzystania kart graficznych do zaawansowanych wysokowydajnych obliczeń miały miejsce w listopadzie 2004 roku. Wtedy zespół naukowców z laboratorium w Los Alamos wspólnie z inżynierami z Nvidii opracował program wykonujący na karcie Nvidia Quadro FX 3400 obliczenia związane z symulacją zapadającej się gwiazdy. Karta graficzna wykonała te obliczenia czterokrotnie szybciej niż procesor Intel Pentium 4 Xeon 3.0 GHz.

W 2004 roku, jako pierwszą do wysokowydajnych obliczeń wykorzystano kartę Nvidia Quadro FX 3400. Symulację zapadającej się gwiazdy wykonała ona cztery razy szybciej od procesora Intel Pentium 4 Xeon 3.0 GHz
Od tego czasu konstruktorzy, początkowo z Nvidii, nieco później również z firmy ATI/AMD, w coraz większym stopniu zaczęli stosować w architekturze kart graficznych uniwersalne i proste procesory RISC, które sukcesywnie zastępowały specjalizowane wyłącznie do obliczeń graficznych moduły, takie jak np. swego czasu rewolucyjne, znane z pierwszego GeForce’a 256 jednostki T&L (Transform and Lighting).
Obecnie wszystkie układy graficzne, zarówno firmy AMD jak i Nvidia zalicza się do procesorów GPGPU (General Purpose GPU). Są to uniwersalne układy ogólnego przeznaczenia, co oznacza, że procesor graficzny GPGPU może być z powodzeniem wykorzystywany zarówno do obliczeń graficznych, jak i zadań typowych dla tradycyjnych jednostek centralnych.
Innymi słowy, w razie potrzeby karta graficzna może wesprzeć procesor komputera podczas wykonywania skomplikowanych obliczeń numerycznych, które nie są w żaden sposób związane z generowaniem grafiki. W wypadku pecetowych kart graficznych są to obecnie obliczenia związane przede wszystkim z fizyką w grach, montażem, kodowaniem i dekodowaniem materiałów wideo oraz poprawą ich jakości lub obróbką zdjęć.
Jednak taka karta graficzna jest w dalszym ciągu nieco lepszą, ale wciąż tylko kartą graficzną. A gdyby tak na bazie karty graficznej zbudować akcelerator obliczeniowy z prawdziwego zdarzenia? Efektem tego pomysłu są opracowane przez Nvidię akceleratory z rodziny Tesla. W jej ramach dostępne są specjalne karty oparte na na zmodernizowanych układach graficznych lub specjalne moduły obliczeniowe, które podłącza się bezpośrednio do serwerów. Co ciekawe, karty oparte na architekturze Fermi (układy z rodziny GF100/GF110), takie jak np. opisany przed chwilą GeForce GTX 580 (GF110) i wcześniejszy GeForce 480 (GF100) zaprojektowano najpierw z myślą o wysokowydajnych obliczeniach, a następnie dodano do nich elementy niezbędne do generowania grafiki.

Akcelerator obliczeniowy Nvidia Tesla C2050
Akceleratory z serii Tesla zostały wprowadzone na rynek jesienią 2006 r. Opierały się na zmodernizowanych układach graficznych 8800 GTX, a ich procesory GPGPU oznaczone były symbolem Tesla T8P. Najnowsze akceleratory obliczeniowe Nvidii opierają się wyłącznie na układach GF100 zgodnych z architekturą Fermi. W sprzedaży dostępne są akceleratory obliczeniowe z wyjściem graficznym DVI, które przeznaczone są do budowy wysokowydajnych obliczeniowych stacji roboczych – Tesla C2050 i Tesla C2070 (modele te różnią się wielkością wbudowanej pamięci – odpowiednio 3 i 6 GB). Dzięki nim standardowy pecet dysponuje mocą obliczeniową zarezerwowaną do niedawna dla superkomputerów i klastrów obliczeniowych.
Akceleratory Tesla zgodne z architekturą Fermi cechują się wydajnością obliczeń zmiennoprzecinkowych o podwójnej precyzji na poziomie 515 GFLOPS (FLOPS – FLoating point Operations Per Second, operacji zmiennoprzecinkowych na sekundę) i ok. 1 TFLOPS w trybie z pojedynczą precyzją. Dla porównania, moc obliczeniowa czterordzeniowego procesora Intel Core i7 965 XE to zaledwie 70 gigaflopów dla obliczeń zmiennoprzecinkowych o podwójnej precyzji i to mniej więcej przy porównywalnej wielkości układu graficznego i tradycyjnego czterordzeniowego procesora.
Jeszcze większymi możliwościami dysponują karty Tesla przeznaczone do centrów przetwarzania danych z serii Tesla M. Karty te są urządzeniami integrującymi kość GPGPU z procesorem sterującym pracą urządzenia. Dzięki temu uzyskano niezależność od platformy systemowej serwera, a komunikacja odbywa się za pomocą magistrali PCI Express. Oczywiście w tym wypadku pozbawione są one złącza graficznego DVI. Najsilniejszy z rodziny M akcelerator Tesla M2090 (zmodyfikowany GF110) oferuje wydajność obliczeń zmiennoprzecinkowych o podwójnej precyzji na poziomie 665 GFLOPS i 1,2 TFLOPS w trybie z pojedynczą precyzją.

Akcelerator obliczeniowy Nvidia Tesla M2090 przeznaczony do montażu w serwerach lub superkomputerach w centrach obliczeniowych
W sprzedaży dostępne są również zestawy Tesla w formie modułów 1U do montowania w szafach stelażowych. Zawierają one do czterech układów Tesla, które są podłączone do przełączników PCI Express, które następnie łączy się za pomocą kabli PCI Express bezpośrednio z serwerem lub superkomuterem. Pierwszym superkomputerem wykorzystującym układy Tesla jest japoński TSUBAME. To hybrydowy klaster składający się z 655 serwerów Sun x4600 oraz 170 serwerów Tesla S1070. Zajął on w 2008 roku 29 miejsce na liście TOP500 najszybszych komputerów świata.

Serwer obliczeniowy w formie modułu 1U do montażu w szafach stetelażowych – Tesla S2070
Procesory Tesla są na tyle szybkie i na tyle dobrze uzupełniają tradycyjne CPU, że coraz częściej wykorzystuje się je do budowy najszybszych na świecie superkomputerów. I tak, zajmujący obecnie na liście TOP 500 drugie miejsce (do niedawna był to najszybszy superkomputer na świecie), znajdujący się od 2010 roku w National Supercomputing Center in Tianjin w Chinach superkomputer Tianhe-1A zbudowany został na podstawie 7168 procesorów Nvidia Tesla M2050 oraz 14336 procesorów Intel Xeon X5670 2,93 GHz. Jego łączna moc obliczeniowa to 2,507 petaflopsa.

Do budowy chińskiego superkomputera Tianhe-1A wykorzystano 7168 układów obliczeniowych z serii Nvidia Tesla M2050. W 2010 ten superkomputer był najszybszą maszyną na świecie
Akceleratory FireStream
Podobną, ale znacznie mniej popularną konstrukcją jest przygotowana przez firmę AMD seria pecetowych kart akceleratorów graficzno-obliczeniowych AMD FireStream, oparta na układach graficznych z serii Radeon HD. Pierwszym akceleratorem, jeszcze pod nazwą ATI FireStrem, czyli przed przejęciem firmy ATI prze AMD, był FireStream 580 oparty na układzie RV580 (Radeon Radeon X1900 XTX). Obecnie w sprzedaży dostępna jest już czwarta generacja akceleratorów AMD FireStream. Są to AMD FireStream 9350 i 9370, które opierają się na układzie graficznym Cypress (RV870) – karty graficzne Radeon HD 5850 i HD 5870. Składają się one odpowiednio z 1440 i 1600 prostych procesorów strumieniowych. Ich moc obliczeniowa to 2016 i 403,2 GFLOPS przy obliczeniach zmiennoprzecinkowych pojedynczej i podwójnej precyzji dla AMD FireStream 9350 oraz odpowiednio 2640 i 528 gigaflopsów dla modelu 9370.

Akcelerator obliczeniowy AMD FireStream 9250 należący do poprzedniej generacji tego typu urządzeń produkowanych przez AMD
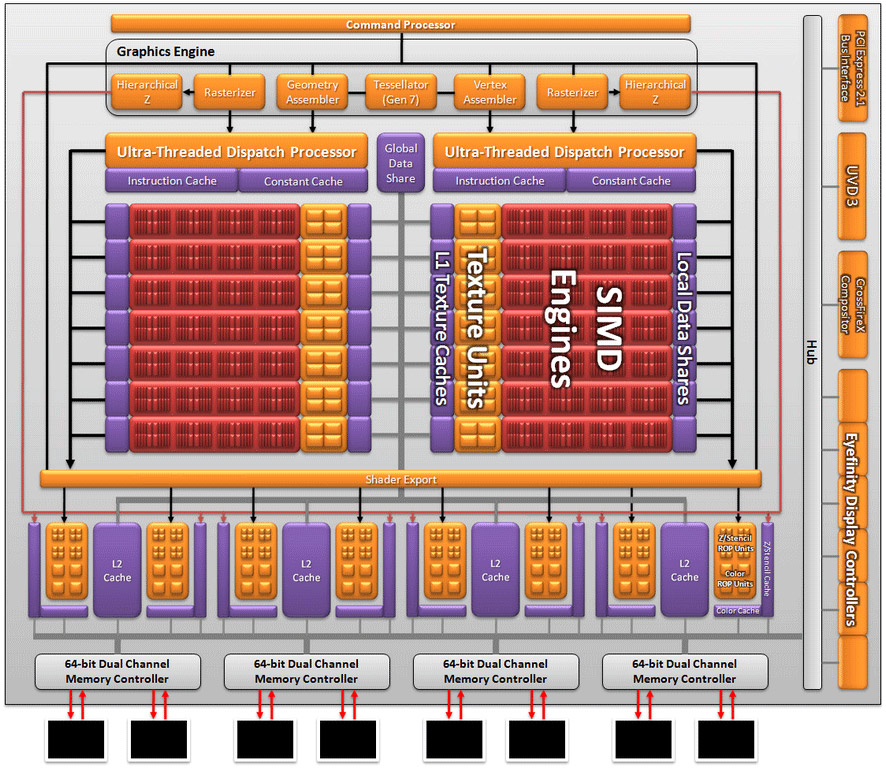
Architektura układu Cypress wykorzystywanego w akceleratorach AMD FireStream. Znane z Redeonów HD 6900 układy AMD Cayman znajdą się dopiero w kolejnej generacji akceleratorów AMD FireStream
Patrząc na powyższe dane nie dziwi fakt, że wielu analityków uważa, że przyszłość wielordzeniowych procesorów związana jest z architekturą GPGPU. Niemniej należy pamiętać, że procesory takie nie mogą wykonywać bardzo szybko wszystkich typów operacji. Głównym obszarem ich zastosowań są obliczenia masowo równoległe (ang. Massively Parallel Computing), w których kilka lub kilkanaście prostych instrukcji przetwarza ogromną ilość napływających strumieniowo danych. Przy typowych dla zwykłych procesorów ciągów instrukcji i skoków warunkowych architektura GPGPU staje się mało wydajna, nawet do kilku razy wolniejsza niż typowy procesor x86.
Dlatego przewiduje się struktury mieszane, na których na jednym kawałku krzemu połączony zostanie układ typu GPGPU oraz kilkurdzeniowy tradycyjny procesor sterujący działaniem jednostki GPGPU. Pierwsze przymiarki do takiej architektury poczyniły już firmy AMD i Intel. Pierwsza z nich, wprowadzając architekturę Fusion (np. układy Llano), druga z układami SandyBridge. Nie są to jeszcze uniwersalne wielordzeniowe wysokowydajne procesory, ale procesory z układem graficznym, niemniej kolejnej ich generacji będzie już bliżej do uniwersalnych układów GPGPU.

Zbudowany na bazie dwóch akceleratorów AMD FireStream 9370 system obliczeniowy firmy SuperMicro

Moduł akceleratora obliczeniowego HP FireStream FS9350 przystosowany do montażu w obudowach serwerów blade z serii HP ProLiant G3




