
W specyfikacji HSA często wspomina się o "inteligentnym" kierowaniu obliczeń do układu, który poradzi sobie najszybciej z danym zadaniem. Wiadomo, że z niektórymi obliczeniami znacznie lepiej poradzi sobie CPU (niewiele wyspecjalizowanych jednostek), a z innymi GPU (wiele prostych jednostek obliczeniowych). Dzięki temu możliwe jest równoczesne zwiększenie wydajności i zmniejszenie poboru energii.
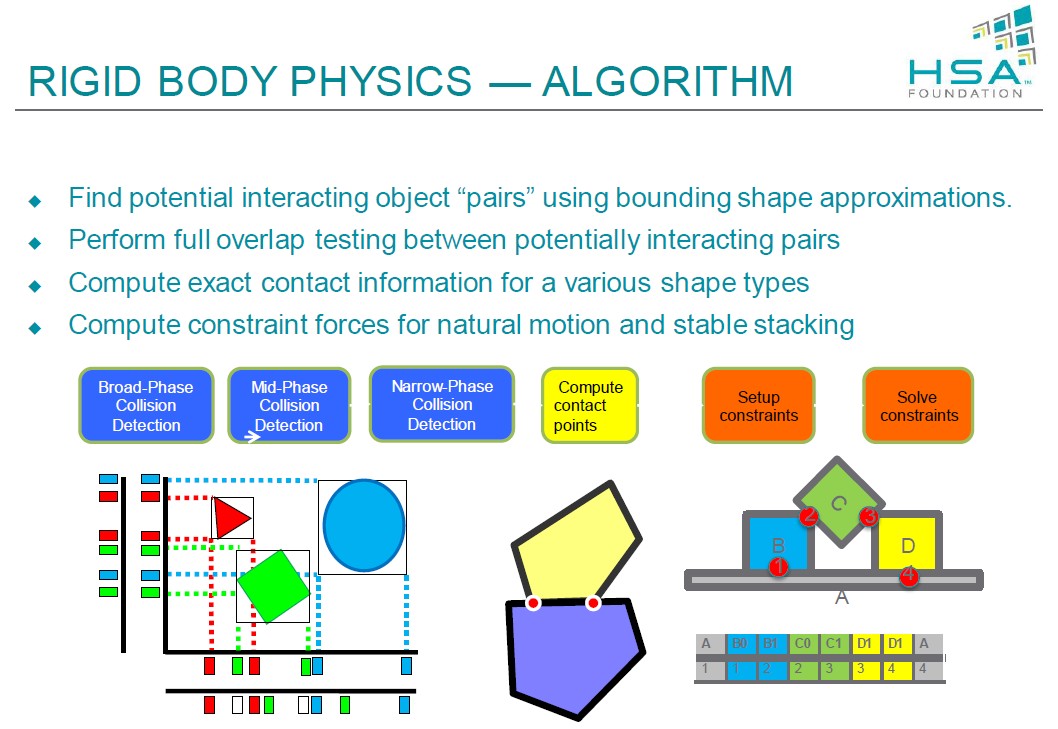
Omówiono również korzyści płynące ze współpracy CPU i GPU na przykładzie silnika fizycznego w grach. Zwrócono uwagę, że obecne algorytmy fizyczne wykorzystujące akcelerację GPU wykorzystywane są wyłącznie w efektach, a nie mają żadnego wpływu na samą rozgrywkę. Dzięki HSA silnik fizyczny będzie mógł kierować obliczenia równocześnie do CPU i GPU operując na tej samej przestrzeni adresowej. Nie trzeba będzie przenosić danych, ale obliczenia do danej jednostki. Każdy układ będzie zajmował się takimi obliczeniami, które będzie mógł wykonać najszybciej.
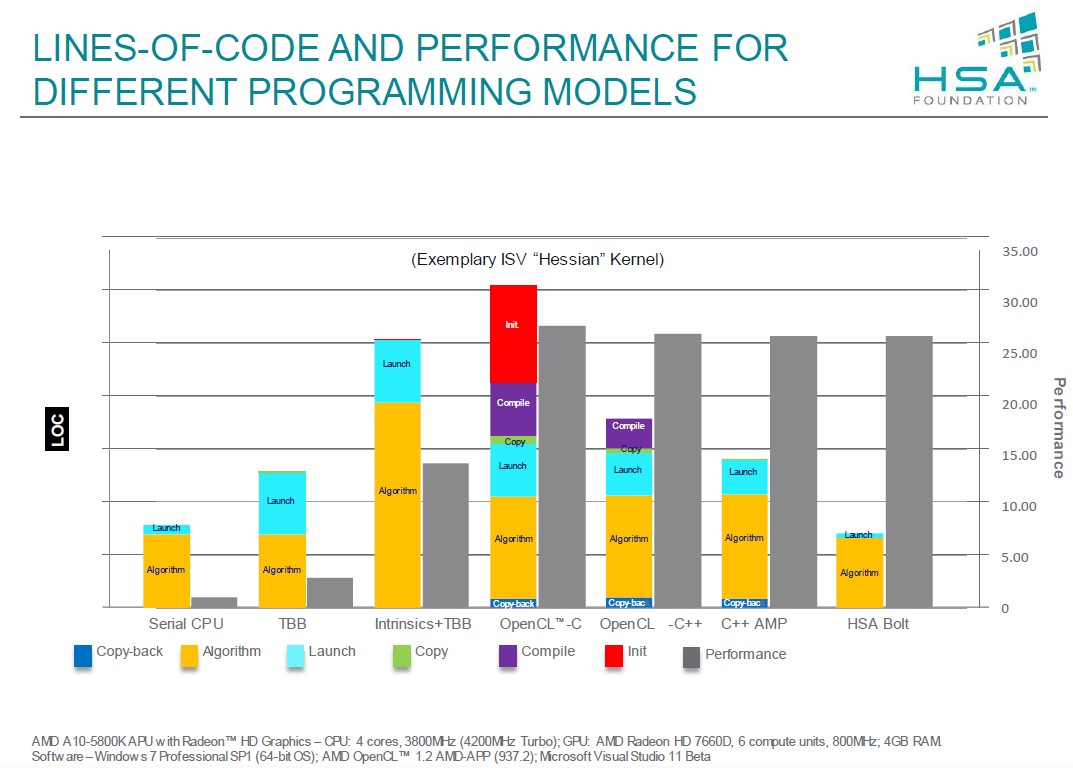
Na zakończeniu konferencji omówiono problematykę długości programu względem jego wydajności. Jak widać na poniższym slajdzie, zastosowanie OpenCL może skutkować znacznym zwiększeniem wydajności, jednak kosztem długości programu. Inaczej mówiąc programowanie staje się bardziej skomplikowane i czasochłonne. Specyfikacja HSA ma doprowadzić do sytuacji, gdy stworzenie oprogramowania wykorzystującego możliwości wszystkich zasobów systemu (CPU + GPU) będzie szybkie i proste, przy potężnym wzroście wydajności.
Tendencja do wykorzystywania obliczeń różnych rodzajów układów może tylko cieszyć. Dzięki architekturze hUMA (zunifikowana pamięć), w której CPU i GPU posiadają równorzędny dostęp do tej samej przestrzeni adresowej, HSA ma zrewolucjonizować działanie układów wyposażonych w różne jednostki obliczeniowe. Plany są ambitne, a prace postępują pełną parą. Pozostaje nam czekać na dalsze szczegóły oraz pierwsze układy wykorzystujące architekturę HSA.





Komentarze
16Co prawda nie zauważyli jeszcze podstawowych problemów takiego systemu, ale w końcu się zorientują i wyjdzie II generacja które będzie 3-4x wydajniejsza na tych samych procesorach ;)
Wygląda na kolejny cudowny wynalazek w stylu JAVA czy C#, który ma przyśpieszyć pisanie programów ale kosztem wydajności w stosunku do dzisiejszych rozwiązań.
Jak wynika z wykresów jedynej słusznej firmy, przyspieszanie wydajności single core stoi pod znakiem zapytania, więc na mizerne przyrosty SB/IVY/HAS narzekacie chyba zupełnie NIESŁUSZNIE!
To może ja :)
Kolorowy słupek to ilość linii kodu (LOC), szary to wydajność.
Serial - szeregowe (nie wiem czy to się tak tłumaczy) rozwiązanie problemu, czytaj: jeden wątek.
TBB - rozwiązanie Intela do rozbicia problemu na wiele wątków (testy były przeprowadzane na 5800K czyli mamy do dyspozycji cztery wątki).
Intristics+TBB - szczerze mówiąc nie wiem, w każdym razie to jest max, co możemy wyciągnąć z CPU.
OpenCL - C - chyba nie trzeba wyjaśniać :)
OpenCL - C++ - j. w. tylko w C++.
C++ AMP - wynalazek Microsoftu.
HSA Bolt - biblioteka do obliczeń heterogenicznych, w sumie to nakładka na OpenCLa, dlatego kod jest krótszy, a wydajność niemal taka sama.