

Co to właściwie jest Big Data
Termin Big Data stosowany jest coraz częściej. Są nawet tacy, którzy wieszczą, iż rok 2013 będzie rokiem Big Data. Ale czym właściwie owe Big Data jest?
Ktoś kiedyś wyliczył, że od czasu, kiedy ludzkość mogła produkować dane, do 2003 roku wyprodukowano pięć eksabajtów danych, czyli 5 368 709 120 gigabajtów. Dużo? A co, jeśli obecnie dokładnie tyle produkujemy co dwa dni? 2 mld internautów w ciągu minuty wrzuca 72 godziny filmów na YouTube, a w ciągu dnia ćwierć miliarda zdjęć na Facebooka – a to tylko najbardziej obrazowe przykłady ogromnej ilości danych produkowanych w ciągu dnia. Jeśli dodać do tego miliardy transakcji bankowych na całym świecie czy informacje o klientach zbierane przez niezliczoną liczbę firm na naszym globie, to ilość danych do przerobienia robi się niewyobrażalna.
Grzechem byłoby tych danych w sposób praktyczny nie wykorzystać. Od dawna, aby stwierdzić epidemię danej choroby, trzeba było zebrać dane na temat tej choroby od wielu lekarzy, a odpowiednie organy sprawdzały, jak zmieniała się liczba chorych – i na tej podstawie stwierdzały, czy liczba ta mieści się w normie, czy już możemy mówić o epidemii. Tak to działa do dziś.

Google wpadło na ciekawy pomysł. Sprawdziło, jak wielu ludzi w krótkim odstępie czasu wpisuje w wyszukiwarkę konkretne frazy, dotyczące np. grypy. Na tej podstawie mogło stwierdzić, że w danym okresie fraza była wyszukiwana częściej. Mało tego, Google było w stanie określić miejsce zamieszkania tych osób. Okazało się, że na tej podstawie można rozpoznać epidemię grypy nawet do dwóch tygodni wcześniej niż metodami epidemiologicznymi.
Zgromadzone dane wykorzystują również banki. Strumień transakcji może być skojarzony z informacjami o użytkownikach serwisu, z informacjami z serwisów śledzących rozwój złośliwego oprogramowania i spamu oraz z danymi z sieci społecznościowych. Udaje się w ten sposób wykryć kampanię phishingową kierowaną przeciw klientom konkretnej instytucji, określić sposób, zakres i jej potencjalne skutki oraz zaplanować wcześniej sposoby przeciwdziałania. Kojarząc transakcje z informacjami o reklamacjach, można także wykryć konta bankowe osób podstawionych (zwanych w Polsce „słupami”). Podstawową zaletą przetwarzania równoległego zasobów Big Data jest szybkość – raporty powstają niemal w czasie rzeczywistym.
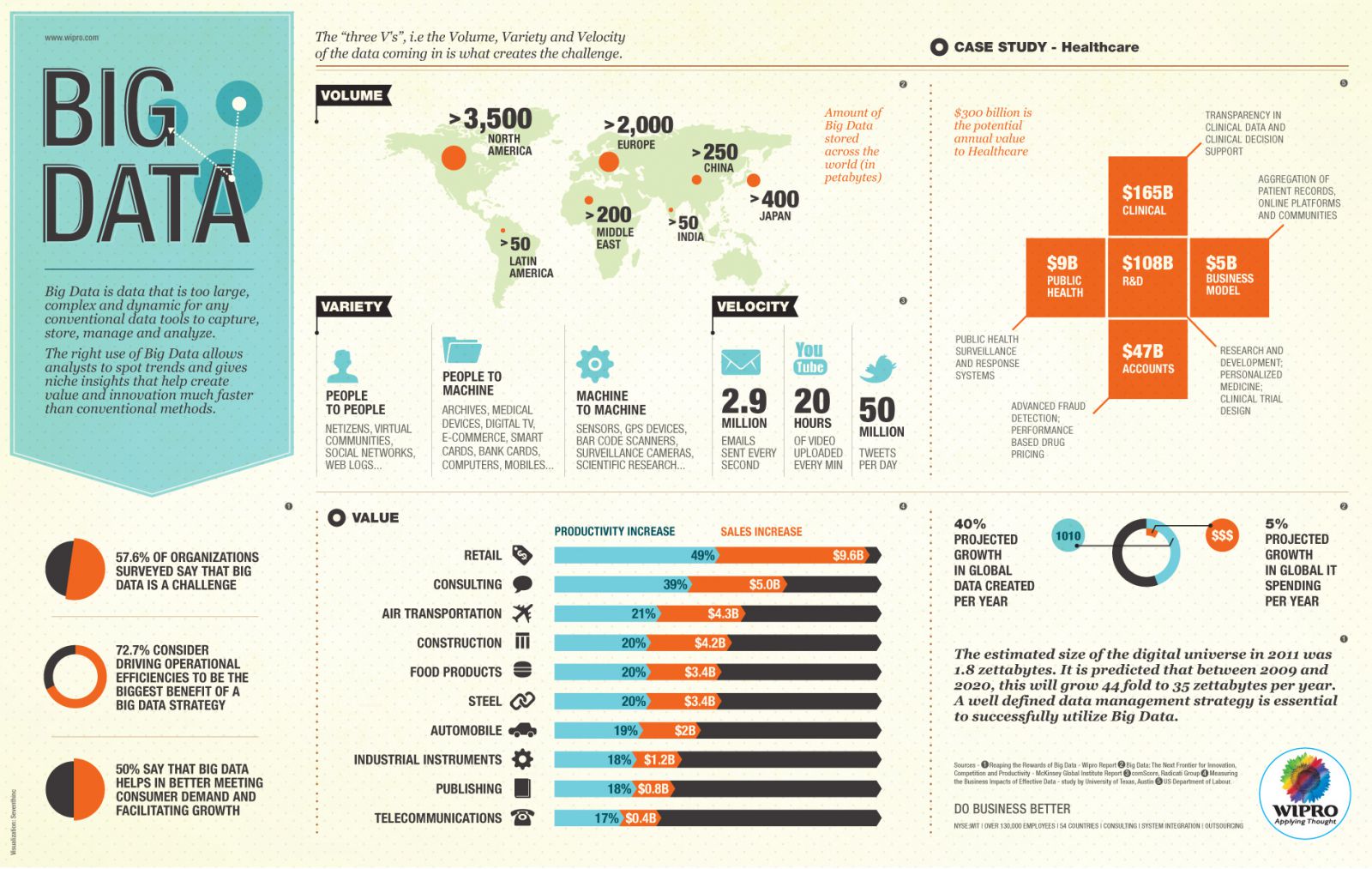

Podsumowując: Big Data dotyczy analizy dużych zbiorów informacji przechowywanych w bazach danych.
Problemy Big Data
Wyobraź sobie, że każdy człowiek na świecie ma zaimplementowany chip wraz z nadajnikiem. Wysyła on do jednego centrum dane na temat składu krwi, moczu, śliny itp. Co sekundę. Dodatkowo analizuje on zawartość naszego żołądka i na tej podstawie określa naszą dietę. Wszystkie te dane odpowiednio przeanalizowane mogłyby pomóc w zdalnej diagnozie naszego ciała, a nawet przewidzieć, kiedy będziemy musieli udać się do lekarza. M.in. takie zadanie stoi przed Big Data.
To prawdziwy przełom. Do tej pory ludzkość jedynie kolekcjonowała dane. Bardzo ciężko było je przetwarzać, umiejętnie wykorzystywać. Big Data to zmienia.
Gromadzenie jednak tak wielkiej ilości danych samo w sobie jest już pewnym problemem. Technologia w pewnym sensie rozwiązuje ten problem, tworząc coraz to większe i tańsze zasoby dyskowe, na które dane te można zapisywać. Prawdziwe wyzwanie przychodzi, gdy chcemy te dane analizować. Potrzeba do tego ogromnych mocy przerobowych, potężnych serwerów i nieograniczonej pamięci RAM. Pół biedy, jeśli jesteśmy dużą światową korporacją i stać nas na wybudowanie własnego data center, co i tak w wielu przypadkach okaże się decyzją nieekonomiczną. Rzadko się zdarza, iż dane te analizowane są w trybie ciągłym. Z reguły analiza odbywa się parę razy w ciągu dnia, nieraz tygodnia, a czasem nawet raz w miesiącu. A poza tym czy analiza dużych zasobów danych powinna być zastrzeżona tylko do dużych korporacji?
Romans Big Data z cloud computing
Z pomocą w analizie dużych zasobów danych przychodzi właśnie cloud computing. To właśnie u podstaw założeń chmury leżą nieograniczone moce obliczeniowe na żądanie. Wykorzystując chmurę, możemy skupić się tylko na analizie danych, nie martwiąc się o potrzebne zasoby sprzętowe. Chmura to także znaczne oszczędności. Płacisz tylko za te zasoby, które w danym momencie wykorzystujesz. Nie martwisz się też konserwacją i utrzymaniem serwerów.
Elastyczność, która jest domeną chmury obliczeniowej ma kluczowe znaczenie w przetwarzaniu dużych danych. – uważa Mateusz Haligowski padawan Apache Hadoop i BigData, wspótwórca projektu otrocloud.com - Sytuacje, w których analizy wykonywane są w czasie rzeczywistym należą do rzadkości. Ciągłe korzystanie z zasobów sprzętowych jest więc zwyczajnym marnotrawstwem, na które w dzisiejszym świecie żadna firma nie może sobie pozwolić. Rozsądniej jest wynająć kilkanaście, a nawet kilkaset serwerów w chmurze na kilka minut, niż pozwolić pojedynczej maszynie mielić dane przez wiele godzin. Patrząc na naszych przodków: żeby szybciej zaorać pole, łatwiej zaprząc dodatkowego woła, niż silniejszego, prawda?
Praktyczne wykorzystanie chmury
Na świecie chmura do potrzeb analiz Big Data jest szeroko wykorzystywana. Case study z udanych zastosowań cloud computingu przedstawia zarówno Rackspace, jak i Amazon.
W Polsce trwają pierwsze, udane próby. Rozwój środowisk związanych z analizą i wykorzystaniem Big Data w Polsce wspiera e24cloud.com. Dlatego zostaliśmy partnerem warsztatów poprowadzonych przez Mateusza Haligowskiego, organizowanych przez 3hack.pl i związanych właśnie z Big Data, które odbyły się 24 listopada w Pomorskim Parku Naukowo-Technologicznym w Gdyni.
Warsztaty miały na celu przedstawienie instalacji i konfiguracji oprogramowania Apache Hadoop oraz oprogramowania wspierającego analizę zbiorów danych o rozmiarach tysięcy terabajtów. Podczas warsztatów użytkownicy zainstalowali oraz skonfigurowali klaster Apache Hadoop z wykorzystaniem Clouder Managera, następnie poznali HDFS i MapReduce, Hadoop: Streaming i Oozie oraz Pig i Hive.
Warsztaty trwały blisko 8 godzin. Ich uczestnicy, korzystając z infrastruktury e24cloud.com, uruchomili 56 wirtualnych serwerów, wykorzystali 297 rdzeni, 592 GB RAM i ponad 17 640 GB przestrzeni HDD. Koszt fizycznego sprzętu zapewniającego wsparcie dla tak wymagających obliczeń wyniósłby dziesiątki tysięcy złotych, ale dzięki zastosowaniu chmury był ponad 10 krotnie niższy.
Publikacje z cyklu Akademia Chmury:
- ABC cloud computingu
- VPS-y, wirtualki i chmury, czyli z poradnika młodego technika
- Postaw na chmurę i zacznij oszczędzać
- Po co w chmurze API?





Komentarze
4